Une machine pensante comme l’homme. Tel est le rêve des uns et le cauchemar des autres. Au-delà des hésitations éthiques et économiques inhérentes à chaque rupture technologique importante, la progression de l’intelligence artificielle, déjà présente dans nombre d’applications que nous utilisons au quotidien, ne cesse de se renforcer.
Comment cette technologie, à l’aube de sa gloire, révolutionne déjà l’industrie, la recherche, le monde médical, le marketing ? La liste est difficilement énumérable tant elle semble se prolonger à chaque seconde.
A l’instar de la prospection pétrolière où les technologies de localisation de nappes ont bousculé l’industrie, le nouvel eldorado de l’information, que le monde a convenu de nommer big-data, où des gisements de données s’amoncellent en quête d’interprétation compréhensible par l’homme, a besoin de nouveaux outils d’exploration.
Sans objectifs d’exhaustivité, cet article propose de parcourir les problématiques naissantes inhérentes à l’utilisation d’algorithmes d’intelligence artificielle dans un contexte industriel, comme par exemple, le projet initié par SNCF Réseau auquel le groupe Talan participe actuellement
Il précisera ensuite le positionnement de tels automates dans l’équilibre des tâches entre l’homme et les machines classiques, et finira par une ouverture sur la roadmap engagée vers des applications d’ IA complètements autonomes.
Le principe fondateur de cette classe d’algorithme est simple, implémenter des modèles mathématiques proches du fonctionnement des réseaux de neurones biologiques permettant, via des « apprentissages », la reconnaissance de concepts (objets dans des images, signatures dans des sons ou autres signaux) avec des degrés de libertés inatteignables via des algorithmes classiques. Des neurones artificiels connectés en réseau (RNA) apprennent donc, soit de manière supervisée, où un expert qualifie une réponse à un stimulus, le logiciel corrigeant sa structure en conséquence pour apprendre ce nouvel élément, ou de manière autonome, non supervisée, où le réseau apprend, dans l’état actuel de l’art, à reconnaître de lui-même des redondances plus ou moins complexes dans les entrées.
Comme évoqué dans l’introduction, l’utilisation de ces algorithmes progresse dans de nombreux cas d’usages. Ils peuvent par exemple reconnaitre avec exhaustivité les objets dans une image et donc décrire une scène de manière automatisée en temps réel, rendant accessible la recherche d’instants dans une vidéo par recherche textuelle, par exemple « y-a-t-il une montagne bleue dans cette vidéo ? ». Au-delà de ses fonctions régaliennes de « reconnaissance de formes », que ce soit dans des images ou des sons, cette capacité à reconnaitre des « structures » dans des entrées a été utilisée récemment par Google DeepMind pour créer une partie de l’automate Alpha Go ayant battu l’humain au jeu de GO.
Dans ce contexte, l’utilisation du mot intelligence pose débat, néanmoins les progrès récents d’apprentissages profonds commencent à justifier ce terme. En effet, nous le verrons dans le paragraphe 4, certains algorithmes sont dorénavant capables de créer des concepts auxquels les hommes de l’art n’avaient jamais pensé. Lorsque la machine commence à concevoir des solutions non pensées mais validées par l’homme, le mot intelligence commence à prendre sens afin de qualifier cette nouvelle autonomie d’analyse allouée aux machines.
Après une émergence remarquée au milieu du XXe siècle, la technologie a graduellement perdu de sa superbe pour ressortir de l’oubli à la fin du siècle dernier grâce à une méthode d’apprentissage, dit « rétropropagation du gradient », ouvrant le potentiel de ces algorithmes. Cette dernière reste le pilier de la technologie et porte encore de nos jours sa progression.
L’engouement récent et « généralisé » pour cette technologie semble le fruit de plusieurs facteurs. Tout d’abord d’innovations comme les réseaux multicouches et les réseaux de convolution (convnet) qui servent maintenant de fers de lance au « deep learning » dans l’image. Ensuite, de la puissance de calcul des clusters actuels qui ont permis la réalisation de réseaux de « deep learning » comptant plusieurs milliards de neurones, gourmands en ressources pour leurs apprentissages. Et enfin, des usages du « web 2.0 » qui ont fait émerger de bases à très fort volume permettant des apprentissages exhaustifs (exemple base d’images taguées par des utilisateurs).
Certaines avancées continuent de renforcer l’avenir de cette classe d’algorithme, notamment une nouvelle génération de réseaux plus proche du fonctionnement des neurones biologiques, les réseaux de neurones impulsionnels. Ces derniers intègrent en plus des réseaux existants la dimension temporelle des stimuli présentés aux neurones, permettant d’enrichir la capacité des réseaux à modéliser les mécanismes de la mémoire des neurones biologiques, mais aussi leur capacité à modéliser des problèmes non-linéaires.
Intéressons-nous aux différences de cycles de vie entre un système d’information classique et un système apprenant. Elles sont majoritairement au nombre de trois. La première constitue une contrainte spécifique de gestion de projet, critique lors du développement d’une solution industrielle basée sur des algorithmes apprenant. Les deux autres sont des avantages intrinsèques aux cycles de vie de telles solutions comparées à des solutions classiques, « non apprenantes ».
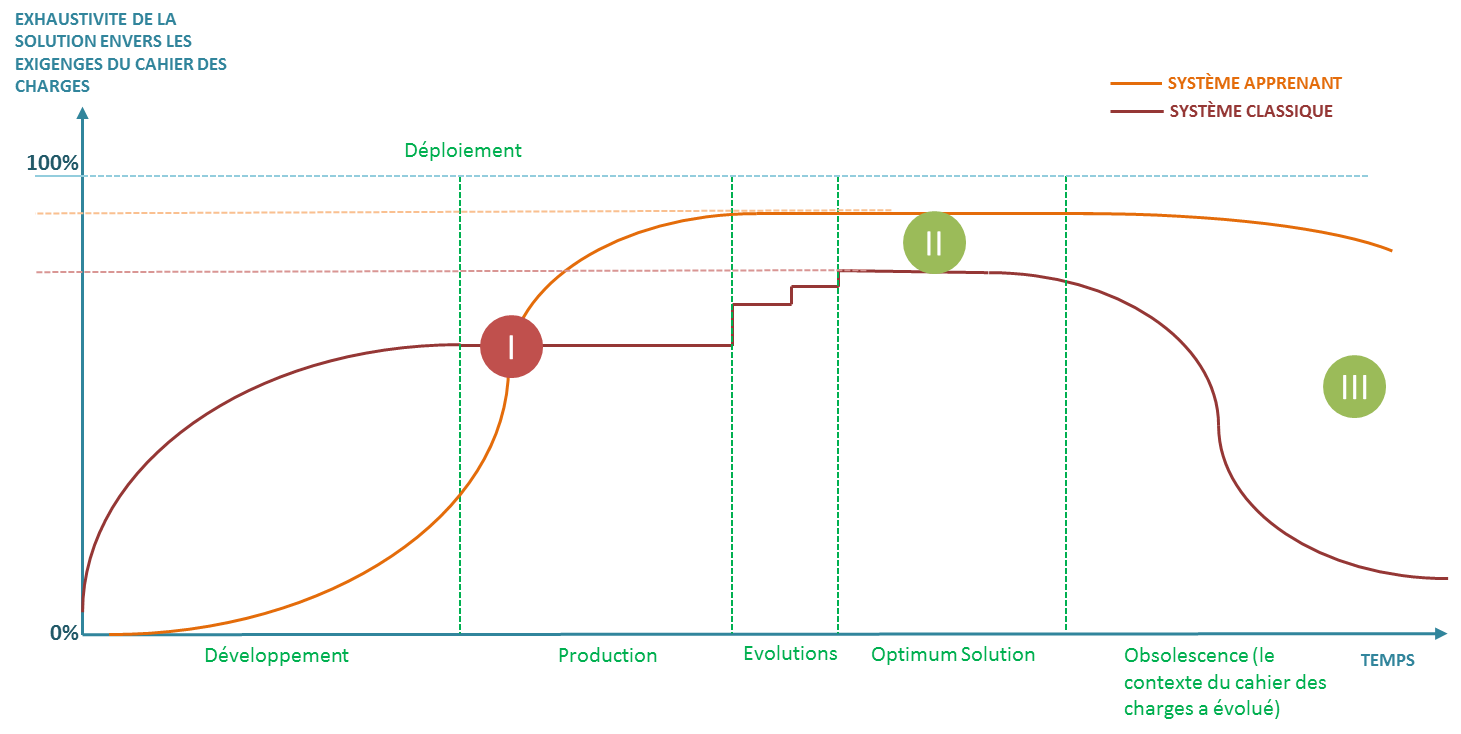
La courbe ci-dessous trace le cycle de vie de la solution, et l’exhaustivité de sa réponse au cahier des charges :
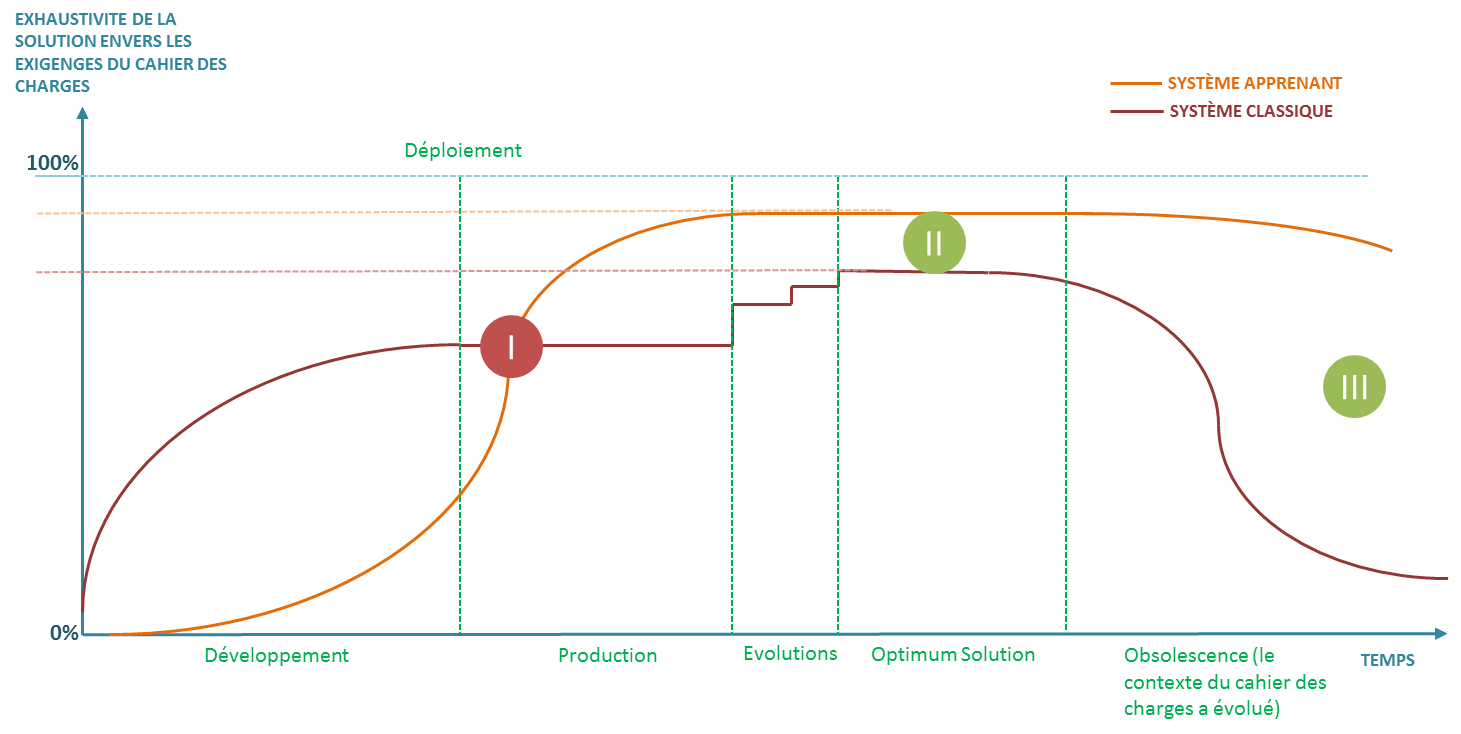
Nous nous apercevons que les processus projets doivent s’adapter au concept d’apprentissage par rapport au développement de solutions classiques.
En effet un système« apprenant» sous-entend un système qui n’est pas opérationnel en pré-production et donc un système qui n’arrivera en « production » au sens fonctionnel, à savoir, une réponse exhaustive au cahier des charges, qu’après un déploiement permettant de réaliser l’exhaustivité de cet apprentissage.
Une validation du système est donc une validation pré-déploiement d’une aptitude à résoudre le problème, cela est légèrement différent de la validation d’un système classique ou l’exhaustivité du résultat est supposée pré déploiement. Au-delà de la validation technologique, cela impose également une stratégie de déploiement radicalement différente, plus progressive, où la rapidité de captation des occurrences des situations d’apprentissages est capitale pour la pérennisation du déploiement, même si la technologie avait éventuellement convaincu à un stade de preuve de concept.
Il est souhaitable, dans la mesure du possible, de produire la preuve de concept sur les situations à apprendre les plus complexes pour fournir aux « décideurs » une « garantie » d’exhaustivité des résultats avant la complétude des apprentissages qui n’arrivera, comme nous venons de le voir, qu’après un déploiement complet
Cela constitue en soi un vrai challenge pour les projets de machine Learning devant faire leurs preuves sur des résultats basés essentiellement sur des simulations, le système n’étant pas encore déployé. Un catalyste possible est d’adjoindre au développement de la solution un environnement de simulation « émulant » un maximum de situations possibles pour réaliser des apprentissages exhaustifs pré-déploiement, cela n’est néanmoins pas possible dans tous les cas d’usage, il faut en effet veiller que les économies de développement accomplies avec des solutions apprenantes ne soient pas absorbées par des coûts de simulations prohibitifs.
Comme vu précédemment, les réseaux de neurones artificiels permettent aux solutions de fournir des résultats beaucoup plus agnostiques au contexte du problème que les solutions classiques. Cette adaptabilité aux conditions opérationnelles permet en général de gagner en robustesse et en exhaustivité face aux exigences du cahier des charges lors de la vie opérationnelle du produit.
Un autre avantage des systèmes apprenants est de rapidement s’adapter à moindre coût à des contextes radicalement différents, sans repenser complètement la solution. Cela étend la durée de vie des solutions et les rend résistantes face à l’obsolescence gagnant généralement les systèmes classiques.
Au-delà des difficultés de la vie du projet, la validation de cette technologie s’accompagne dans certain cas d’une nécessite de caractère GAME (globalement au moins équivalent) à un système existant, qu’il soit un algorithme existant ou une tâche dévolue à un agent. Il est donc important de comprendre les avantages intrinsèques des systèmes apprenants.
Des univers normés comme SNCF Réseau (Cf. article sur le Blog Cereza), où la sécurité est omniprésente et à la racine des décisions technologiques, constituent un stress-test solide pour cette technologie.
Nous entrons dans une phase où elle doit prouver, dans un premier temps, dans un cadre « non sécuritaire » d’aide à la décision, une fiabilité « globalement au moins équivalente » aux algorithmes existants ou à une analyse humaine.
La perception “boîte noire” des algorithmes de machine Learning est souvent à la source d’un questionnement sur leur positionnement dans l’accomplissement des tâches par rapport à l’homme ou aux systèmes que l’on qualifiera de “classiques”. La représentation abstraite suivante permet de définir les différences “fonctionnelles” d’une analyse accomplies par ces différents systèmes.
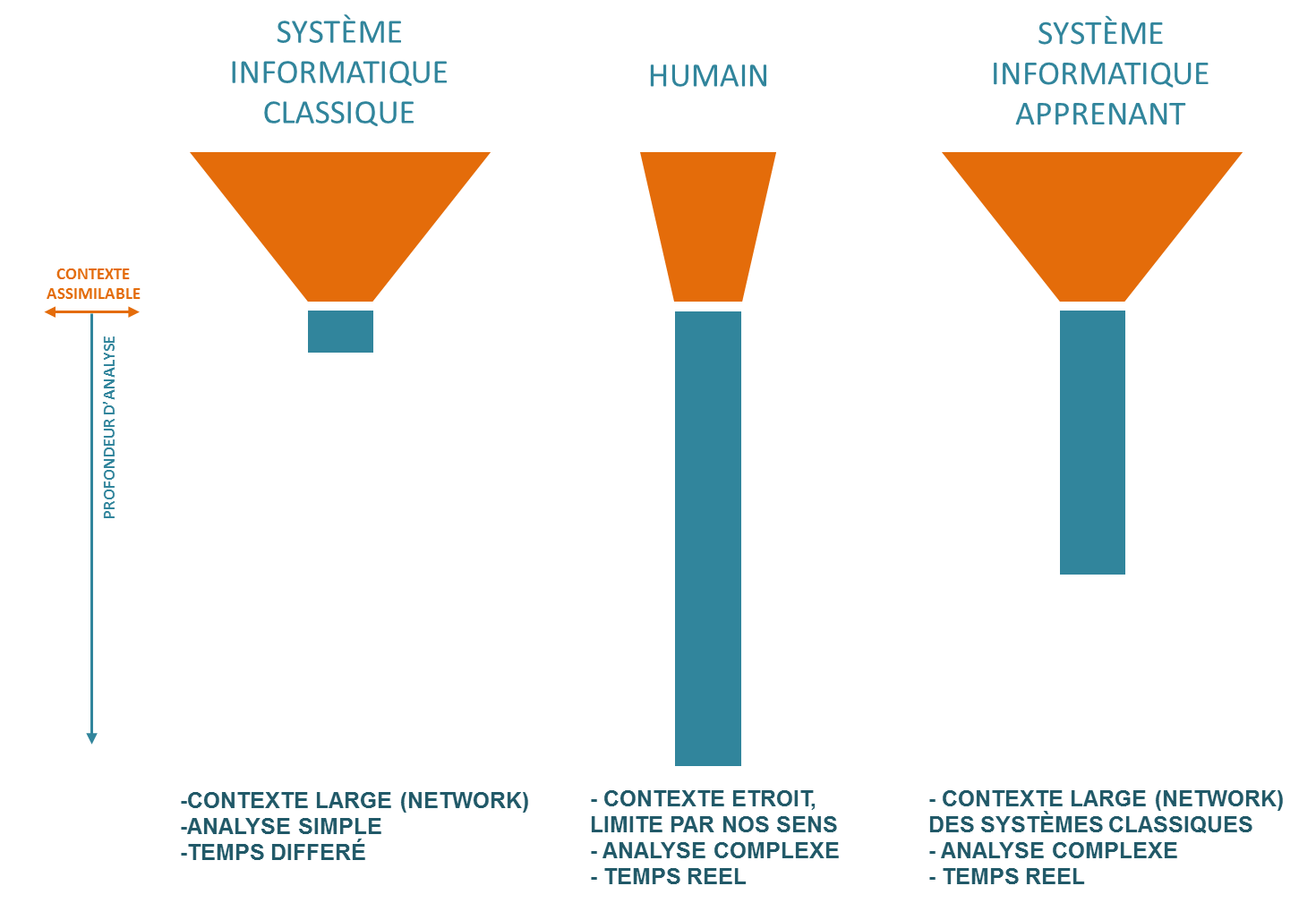
L’avènement de l’informatique, souvent qualifié de révolution industrielle, a bouleversé les processus de gestion et de traitement de l’information jusqu’à engendrer la société que nous connaissons actuellement. Les possibilités d’interconnections des systèmes leur ont permis de s’affranchir des limitations que l’homme subit dans sa corporalité. En effet notre physionomie nous empêche de nous combiner, et de former un réseau, ou un ensemble de cerveaux incrémenteraient une capacité de calcul en réseau local. L’informatique classique a donc permis, par cette qualité, de capter beaucoup plus de contexte qu’un humain pour répondre à un problème. A ceci près que la perception des algorithmes classiques est très dépendante du contexte, un exemple étant qu’un algorithme classique de reconnaissance d’objet aurait du mal à reconnaître une pomme dans un contexte changeant, ce qui ne pose aucun problème pour l’homme qui reconnaitra un concept peu importe le contexte.
La réponse à un problème donné dépend de 2 critères fondamentaux, la masse de contexte admissible par un système, où, comme nous l’avons vu, l’informatique classique possède un avantage sur l’homme, mais également la profondeur d’analyse, que certains pourraient ramener à une capacité d’abstraction et de conceptualisation. C’est précisément sur cet aspect que l’homme conserve son net avantage et produit des analyses beaucoup plus complexes que des algorithmes.
Les réseaux de neurones artificiels sont capables de se combiner pour faire émerger des concepts à l’instar du cerveau humain, mais également des liens entre ces concepts et ce, sans que l’homme n’ait à expliciter quelque règle que ce soit sous forme de code. Ils sont donc capables d’abstraitiser des stimuli comme les humains et sont en ce sens capables d’analyses beaucoup plus profondes que les algorithmes classiques. Ils sont néanmoins loin d’être aussi capables que le cerveau humain dans cette manipulation de concepts pour résoudre des problèmes. Ils bénéficient par contre de l’avantage de leurs aïeux classiques d’une capacité de capter un contexte étendu par rapport à l’humain et produisent ainsi des « raisonnements » inédits, complexes, et inaccessibles au cerveau humain.
L’exemple marquant est la prolifération dans le domaine médical, notamment par l’université de Stanford, d’études montrant que des algorithmes de « deep learning » produisent des analyses inédites de tissus cancéreux en y détectant des signaux précurseurs dans les tissus environnants , signaux difficilement détectables par les hommes de l’art.
Il est important de préciser qu’ « intelligence » dans la plus part de cet article réfère à la « capacité à résoudre un problème » nous laisserons pour l’instant la « quête d’un état de conscience » de côté, l’intelligence artificielle générale étant encore hors de portée des algorithmes de « machine Learning » actuels.
Cette combinaison de « digestibilité » de données massives couplée à une certaine capacité d’abstraction donne au couple « Machine Learning » + « Big-Data » une valeur économique conséquente, sans pour autant avoir des systèmes « profondément » intelligents. Ces capacités algorithmiques nouvelles sont d’autant plus intéressantes qu’elles sont rapides. En effet, leur rapidité leur permet des temps d’analyse sur des contextes larges en temps réel alors que les algorithmes classiques digèreraient cette masse de donnée dans un temps relativement plus long..
La prochaine étape pour ces algorithmes est d’apprendre par « eux-mêmes », de gagner en autonomie pour créer des concepts ex-nihilo sans que l’homme n’intervienne comme « guide » ou « professeur », c’est ce que l’on appelle les algorithmes autoapprenants.
Dans une époque où l’augmentation de la capacité de calcul passe par une augmentation de l’infrastructure et son interconnectivité, il a souvent été de mise de comparer l’efficience énergétique des systèmes informatiques à celle du cerveau humain et de constater le gouffre énergique des clusters de calcul pour des fonctions que l’homme accomplit sans effort à très faible coût énergétique. Nous entrons alors dans le monde de la performance par watt, ou devrait-on dire, de l’intelligence par watt. Là encore les RNA permettent des analyses complexes à très faible coût énergétique. Il est alors possible d’embarquer des traitements très complexes « on chip » sur des processeurs que l’on qualifie de « neuromorphiques » avec les avantages d’un traitement temps réel de l’information et des gains en bande passante du fait de la communication du seul fruit de l’analyse sans obligation de communication de la source ou stimuli. Bien évidemment, l’intelligence des RNA étant scalable, il fait sens pour certaines applications de centraliser le réseau de neurones sur une infrastructure centralisée de plus grosse taille pour une analyse plus complexe, cela dépend donc du cas d’utilisation, mais il faut retenir que le bond en performances par watt des RNA a permis l’émergence d’une multitude d’applications embarquées inaccessibles aux systèmes classiques.
Bien évidemment, une telle révolution ne va pas sans restructurer des faces entières de l’économie. Il est dès lors tout naturel que la physionomie du marché des ESN (Entreprises de Services Numériques) s’adapte à ces nouveaux outils.
Deux caractéristiques, le concept d’apprentissage d’une part, et l’aspect générique de la technologie d’autre part, vont faire évoluer le métier de développement informatique ainsi que le conseil en management des systèmes d’informations.
L’apprentissage met donc en scène des experts métiers devant des plateformes pour « apprendre » à la machine directement la fonctionnalité métier recherchée, sans passer par une étape de développement, ce dernier étant implicitement « encodé » par l’algorithme d’apprentissage. Il est à noter que les RNA actuels nécessitent encore l’intervention d’un « architecte » RNA pour suggérer la meilleure structure de réseau pour apprendre le cas d’usage, mais un réseau générique suffisamment flexible pour accueillir une diversité de cas d’usages métier est de plus en plus « réalisable ».
L’intelligence artificielle transfère donc un coût et temps élevé de développement externalisé vers un coût et temps réduit d’expertise interne à l’entreprise.
Une partie du marché de développement va donc graduellement disparaître, les ESN peuvent couvrir cette perte par soit, offrir leur propre plateforme « intelligente », soit par de l’AMOA spécialisée dans le déploiement de solutions de « machine Learning ».
Les algorithmes autoapprenants, au gré de leurs perfectionnements, vont, dans un premier temps, permettre l’automatisation de tâches complexes où l’improvisation est sollicitée plus que la répétition. Cela va bien évidement contribuer à remplacer l’homme dans de nombreux services.
Mais la recherche est encore longue avant d’arriver à une intelligence artificielle générale, et plusieurs facteurs sont peut-être, sans le savoir, en train d’en ralentir ces efforts.
Le premier est que l’homme crée pour son propre « confort » et surtout pour ses propres capacités d’interprétations des résultats, or, cette part systémiquement “anthropomorphique” dans nos solutions bornera potentiellement les raisonnements de ces algorithmes, là où la machine pourrait éventuellement nous dépasser. Il faut donc que l’homme centre sa recherche fondamentale pour fusionner le meilleur de notre biologie avec celui d’une intelligence dématérialisée i.e., s’inspirer de l’humain sans s’y confiner, ce dernier ayant été « construit » sur un ensemble d’organes « limités » fournissant les stimuli.
Les briques de bases que sont les modèles mathématiques des réseaux de neurones artificiels doivent également encore progresser pour arriver au niveau d’un cerveau humain, les limitations actuelles étant dans la manière dont se propage l’information dans les réseaux de neurones artificiels (feedforwarding only) et la nécessité de forts volumes de données pour l’apprentissage, les réseaux actuels n’étant pas encore capables d’apprendre sur très peu d’exemples.
Enfin, l’industrie sort petit à petit du biais introduit par l’informatique actuelle dite booléenne de ne pas tolérer l’erreur. Les exemples d’introduction d’hardware/software bayésien tolérant des taux d’erreurs non négligeables se multiplient, allant des efforts d’informatiques quantiques à des solutions utilisant les processus de fonderie actuels, comme le PCMOS pour Probabilistic CMOS introduit par l’université de Rice où un processeur tolérant 8% d’erreur a doublé ses performances et réduit sa consommation énergétique de 30% [http://www.ece.rice.edu/~al4/visen/2006date.pdf].
Cette aversion à l’erreur est encore un réflexe naturel et les résultats exigés des RNA sont également extrêmement élevés avec des niveaux de réponses de l’ordre de 99,5%. Ces scores sont effectivement à rechercher pour les domaines où l’homme opère également à ces niveaux, comme la reconnaissance visuelle, mais la recherche en cognition et raisonnements artificiels ne doit pas se structurer autour de la quête d’un taux d’erreur de 0,1%. En effet, l’homme vit constamment avec l’erreur, si nous devions quantifier le taux d’erreur de nos « choix » et « raisonnements », il serait probablement plus autour de 60%, légèrement au-dessus d’un résultat « aléatoire » (l’évolution nous ayant doté de ces capacités, elles doivent probablement avoir une valeur ajoutée par rapport à l’aléa pur) mais avec un taux d’erreur relativement important.
Au-delà de ces quelques limitations, cette intelligence artificielle généralisée, proche de l’homme, reste l’obsession d’une poignée de chercheurs à la convergence des neurosciences (retro-engineering de l’activité/structure cérébrale, de la mémoire), des mathématiques (progrès sur le modèle) et de la psychologie/psychanalyse (fonctionnement des concepts humains) et sera sans nul doute parmi les plus intrigantes inventions que le futur nous réserve.
