
Cet article s’insère dans notre série « Chaos Engineering ».
Le jeudi 31 Mai 2018 s’est tenu le méta-meetup “DevOps Night #3” au sein des tours de la Société Générale à la Défense. Cette réunion était conjointement organisée par 4 grands meetup parisiens autour d’un même sujet : “le DevOps”.
Pour cette troisième édition, la keynote a été réalisé par la dernière communauté à avoir rejoint le méta-meetup, je veux parler des animateurs du meetup “Chaos Engineering” : Christophe Rochefolle (@crochefolle) et Benjamin Gakik (@BenjaminGakic).
Comme à leurs habitudes, les deux “Chaos Engineer” de oui.sncf, on le chic pour attirer l’attention aussi bien des Dev que des Ops autour de leurs activités préférées : “semer volontairement le chaos dans une production informatique”
Le Chaos Engineering est la discipline de l’expérimentation sur un système distribué afin de renforcer la confiance dans la capacité du système à résister à des conditions turbulentes en production [wikipedia & principlesofchaos.org]
Heureusement, leurs définitions et leurs présentations sont largement plus “friendly” que la définition de Wikipédia. Parce que (franchement) qui trouve le suivi de production intéressant ??. Je dirais tout ceux qui ont déjà vu la présentation de Christophe et Benjamin par exemple à Devoxx ou à DevopsRex (sur YouTube). Et pourquoi pas vous, si vous ne les avez jamais rencontrés ?

Ma citation préférée de cette keynote est tirée d’un ouvrage de Chaos Engineering, Building Confidence in System Behavior through Experiments (ebook disponible : https://www.oreilly.com/webops-perf/free/chaos-engineering.csp)
“Introducing Chaos is not the best way to meet your new colleagues, though it is the fastest.” Nora Jones (@nora_js)
Comme c’est un meta-meetup, il y avait donc un choix à faire entre l’une des 4 associations. A l’image d’un hackathon, chacun leur tour a fait un “pitch” pour attirer évidement le plus de monde. Voici ce qu’il y avait au programme de la soirée :
Pour ce cinquième rendez-vous, ils nous ont invité dans les coulisses de l’organisation d’un jeu qui s’appelle le “day of chaos”. Les règles sont assez simples : “Toutes les 30 minutes, des exploitants (ou OPS) simulaient des pannes en pré-production. Les équipes de DEV obtenaient des points en fonction des détections, des diagnostics et des résolutions”. Ce type d’événement gamifié permet d’initier les équipes de développement au concept de résilience et au suivi de production.
 Nous avons donc été mis dans la peau des exploitants qui doivent trouver des pannes à proposer à nos équipes de DEV. On a donc travaillé sur des pannes réelles et sérieuses qui sont apparues chez les participants.
Nous avons donc été mis dans la peau des exploitants qui doivent trouver des pannes à proposer à nos équipes de DEV. On a donc travaillé sur des pannes réelles et sérieuses qui sont apparues chez les participants.
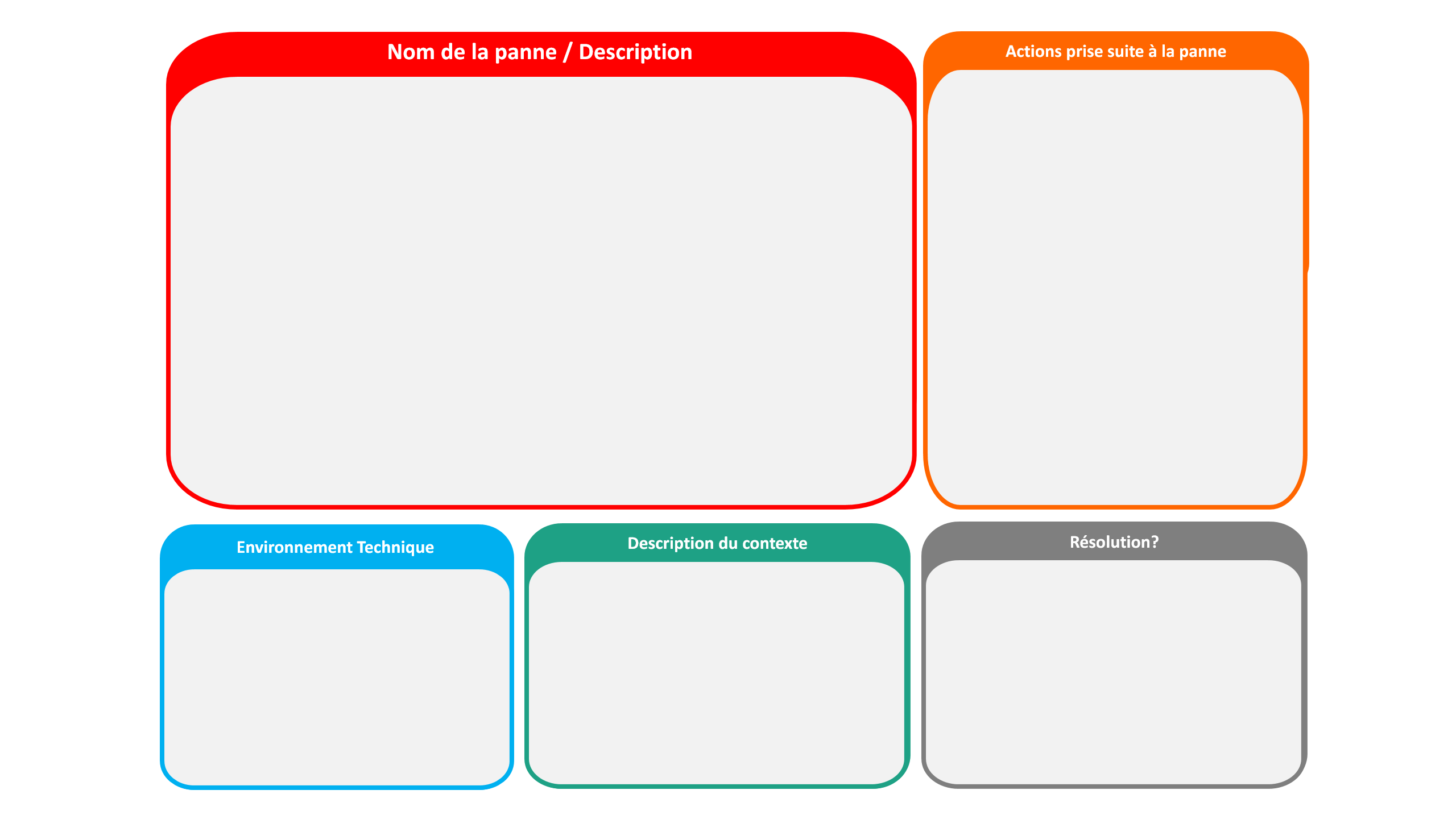
Le déroulement est assez simple : en petit groupes de travail, on a commencé par identifier une panne qui a causé de gros problèmes parce que l’application n’était pas assez résiliente. Pour nos incidents, il a fallu remplir un premier template. On a donné un “petit nom” à nos pannes parce que c’est tout de suite plus amusant de travailler sur “VM Vampire” que sur “une VM consomme toute les ressources et reboote en boucle”. On a détaillé le contexte, l’environnement technique, les actions qui avaient été prise à la suite de la panne et indiqué si oui ou non nous l’avions résolu.
Dans l’état d’esprit du Chaos Engineering, il faut expérimenter la panne à reproduire ! Alors, ce fut la seconde étape “Expérimentation”. Toujours sur le même principe, un petit groupe découvre la panne et propose une action à mettre en place. Nous avons commencé par la base : avoir un but, savoir qui sera impacté ? Quoi mesurer et comment le monitorer. On a également pris en compte la cible et le résultat attendu car toutes actions doivent avoir une raison valable ! Le chaos engineering ce n’est pas seulement pour s’amuser à démolir un système informatique, c’est trouver les solutions pour devenir tolérant aux pannes 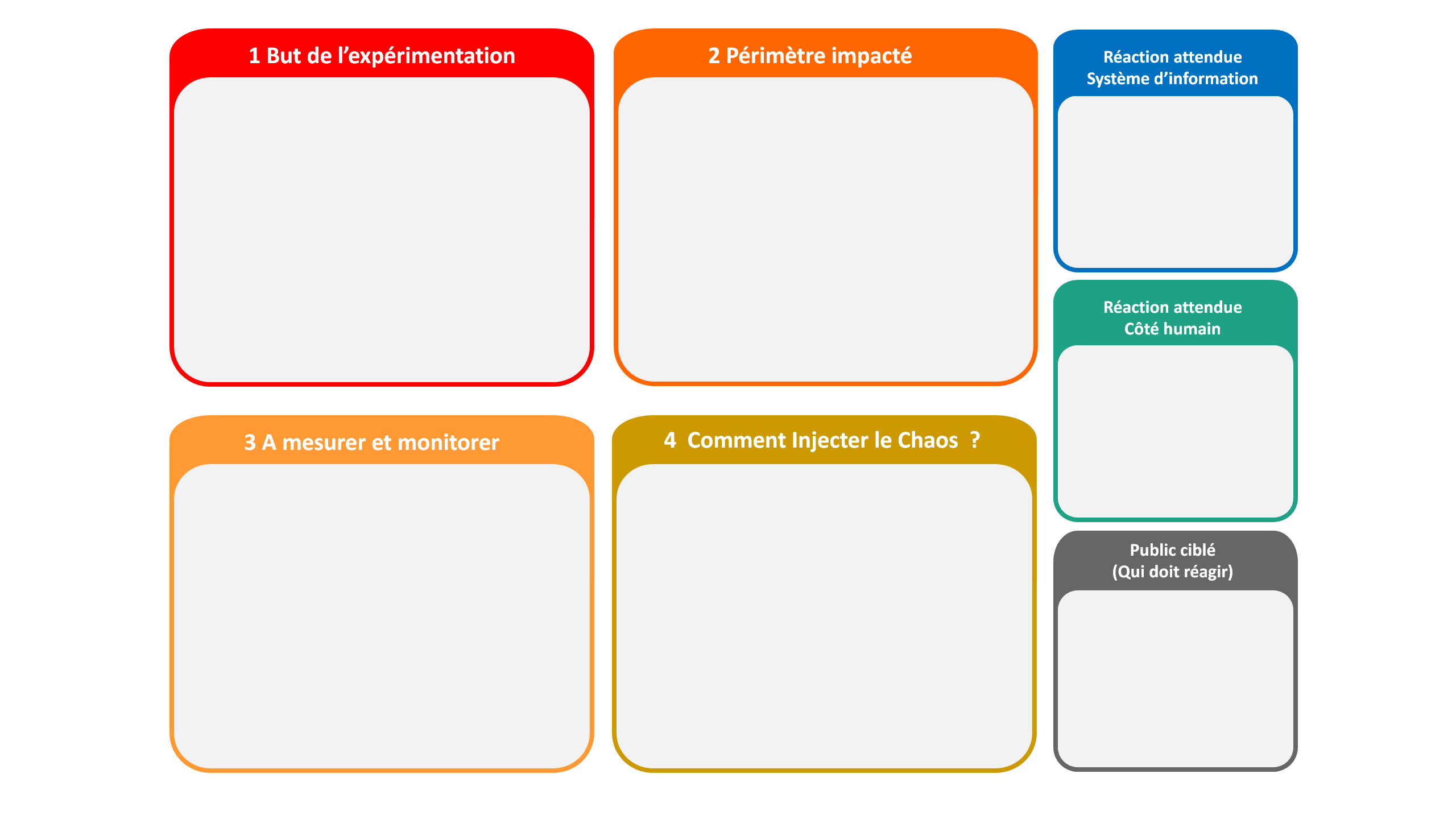
Comme toute les bonnes choses ont une fin, on a fait un tour de table pour présenter les “Incidents & expérimentations” des tous les groupes de travail. Si vous voulez la synthèse, venez les voir au prochain meetup Chaos Engineering.
Vous pouvez les retrouver à Agile France le 15 et 16 juin ou lors du prochain meetup de Septembre pour parler des patterns de résilliance! Il y a également un groupe sur Medium à suivre (https://medium.com/paris-chaos-engineering-community) et un slack (https://days-of-chaos.slack.fr)
Vous avez aimé cet article ? Découvrez ou redécouvrez l’autre épisode de la série « Chaos Engineering » :
Le chaos engineering (https://blog.talanlabs.com/le-chaos-engineering/)
