
Je me suis remis à ElasticSearch après plusieurs années d’absence et le choc a été dur : revenir à Oracle après 5 ans, pas de souci, mais dans le cas d’Elasticsearch, ça avait tellement évolué que j’ai du prendre un peu de temps pour m’y remettre.
Que s’est-il donc passé entre un ES 0.90.5 de 2013 et un ES 6.5.4 de 2019 ?
En 2013, je travaillais chez Cadremploi et nous avions besoin de faire évoluer le moteur de recherche du site qui fonctionnait uniquement avec Lucene. La promesse d’Elasticsearch : un cœur Lucene, une recherche simplifiée (la syntaxe Lucene est étrange) disponible par une API REST et une base de données distribuée répliquée automatiquement. Le projet avait été un succès et avait été mis en production par l’équipe suivante.
Retour à ElasticSearch chez GrDF qui souhaite accélérer sa recherche dans une de ses bases clientes. Environ 30 millions de clients présents dans la base et des nouveaux besoins de recherche : une recherche libre “à la google” ainsi qu’une recherche par préfixe.
Voyons maintenant ces changements qui m’ont marqué.
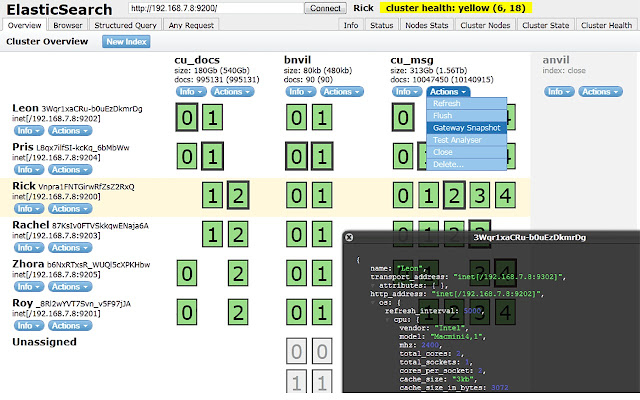
En 2013, la meilleure façon de visualiser son cluster ElasticSearch était d’utiliser un plugin “site” comme head ou kopf (notez le lien entre les deux). Une fois installée, ElasticSearch servait directement ces pages web sur son port 9200 (par défaut). Il y en de toute sorte, du monitoring de cluster aux tests des plugins phonétiques. En octobre 2016, la version 5.0.0 d’ElasticSearch sonnait la fin des plugins site notamment à cause de problèmes de sécurité (ici et là). Désormais, il faut embarquer un serveur indépendant pour pouvoir distribuer une fonctionnalité annexe à ElasticSearch. C’est peut-être un peu contraignant, mais cela garantit une vraie indépendance des produits, indispensable quand on passe en production.
A noter que Kibana fournit un monitoring basique dans sa version gratuite.
Une façon d’alimenter ElasticSearch était d’utiliser une river, c’est à dire un batch intégré à ElasticSearch capable de parcourir plus ou moins fréquemment une source pour en extraire les données. Il y en avait plusieurs, en particulier pour extraire des données d’une base de données (à partir d’une requête), de CouchDB, RabbitMQ, Wikipedia ou encore Twitter. Le problème venait de la consommation des ressources nécessaires (mémoire, sockets…) au bon fonctionnement du batch au détriment du fonctionnement d’ElasticSearch. En mars 2015, la version 2.0.0 les fait disparaitre et ElasticSearch propose soit d’extraire le code des rivers pour externaliser le fonctionnement ou d’utiliser LogStash comme solution d’approvisionnement.
Même si les rivers wikipedia ou twitter revêtaient un caractère pratique pour remplir sa base, dans un contexte de production, il y avait une vraie appréhension à en utiliser une, la question de la reprise sur erreur en cas de crash du nœud hébergeant la river étant difficilement solvable.
Le TTL (time to live) est une fonctionnalité que l’on retrouve dans de nombreuses SGBD : lorsque vous ajoutez une donnée, vous pouvez préciser sa durée de vie. Une fois le temps écoulé, le système supprime automatiquement cette donnée.
Ce mécanisme peut sembler séduisant mais il présente de nombreux inconvénients : il faut fréquemment (60s) parcourir l’ensemble des données pour détecter celles à supprimer mais également “recompacter” les fichiers dans lesquels on supprime ces données. Le champ _timestamp (date d’insertion de la donnée) est utilisé pour calculer le ttl. La version 5.0.0 d’ElasticSearch supprime cette fonctionnalité précédemment dépréciée. Il est conseillé d’utiliser sa propose date au lieu du champ timestamp (si nécessaire) et d’utiliser des index temporels pour “partitionner” les données. De cette manière, il est facile de supprimer les données ajoutées au même moment en supprimant directement l’index.
Si vous avez cependant besoin de définir des durées de vie différentes en fonction de vos données, il faudra gérer le mécanisme à la main : créer un champ spécial et appeler manuellement une requête “delete_by_query”. Ce sera toujours plus efficace qu’avec un ttl car le parcours et la suppression des données ne se fera qu’une seule fois (et en utilisant les index).
De manière générale, je pense que les TTL sont une fausse bonne idée : ils dégradent les performances et une meilleure conception de sa structure de données permet d’anticiper la question du nettoyage des données.
De nombreux types de données sont disponibles dans ES (dates, numériques, les tableaux…).
Le type string, qui représente une chaîne de caractères, a vu son fonctionnement évoluer avec la version 5.0.0 (toujours la même).
Celle-ci introduit la séparation du type string en text et keyword. La nuance est importante car elle est influence directement la manière dont on recherche les données :
Ces nouvelles notions sont intéressantes car elles nous encouragent à mieux penser notre schéma de données en gardant bien à l’esprit que la question la plus importante est “comment je veux chercher mes données”.
En étant légèrement grossier, on pourrait dire que les mapping types sont à un index Elasticsearch ce que les tables sont à un schéma sur une base de données. On peut créer plusieurs mapping types sur un index, ce qui n’implique pas pour autant de jointure. La version 7 d’ElasticSearch va déprécier cet usage qui sera supprimé dans la version 8.
Pourquoi ? Parce que lorsque sur un même index, on a deux mapping types différents mais que des champs ont le même nom (par exemple une date), ces champs doivent être de même type (string, int…). On peut supposer qu’une date sera toujours du type date, mais parfois, on va avoir un long, une string…
La solution de contournement ? Un index pour chacun des mapping types (qui s’appelle tous _doc). Elasticsearch permet de requêter dans plusieurs index en même temps (et même sur plusieurs clusters).
Je me rappelle encore de ma première installation d’ElasticSearch : lors du premier démarrage, je regarde les logs et je vois le serveur commencer à discuter avec pleins de machines…mais que se passait-il ?
La raison était très simple : par défaut ElasticSearch était configuré en mode multicast, c’est à dire qu’il demandait sur le réseau si des copains voulaient bien jouer avec lui…autant dire que la première étape était de couper son serveur et d’aller voir la doc (ce que j’aurais surement dû faire depuis le début…)
La version 5.0.0 supprime le plugin multicast, il faut désormais configurer le champ discovery.zen.ping.unicast.hosts afin de définir les nœuds à contacter (par défaut à 127.0.0.1).
En 2013, ElasticSearch était un produit isolé autour duquel gravitaient des outils de la communauté : des plugins, des outils. Kibana en est un parfait exemple (outil de dataviz).
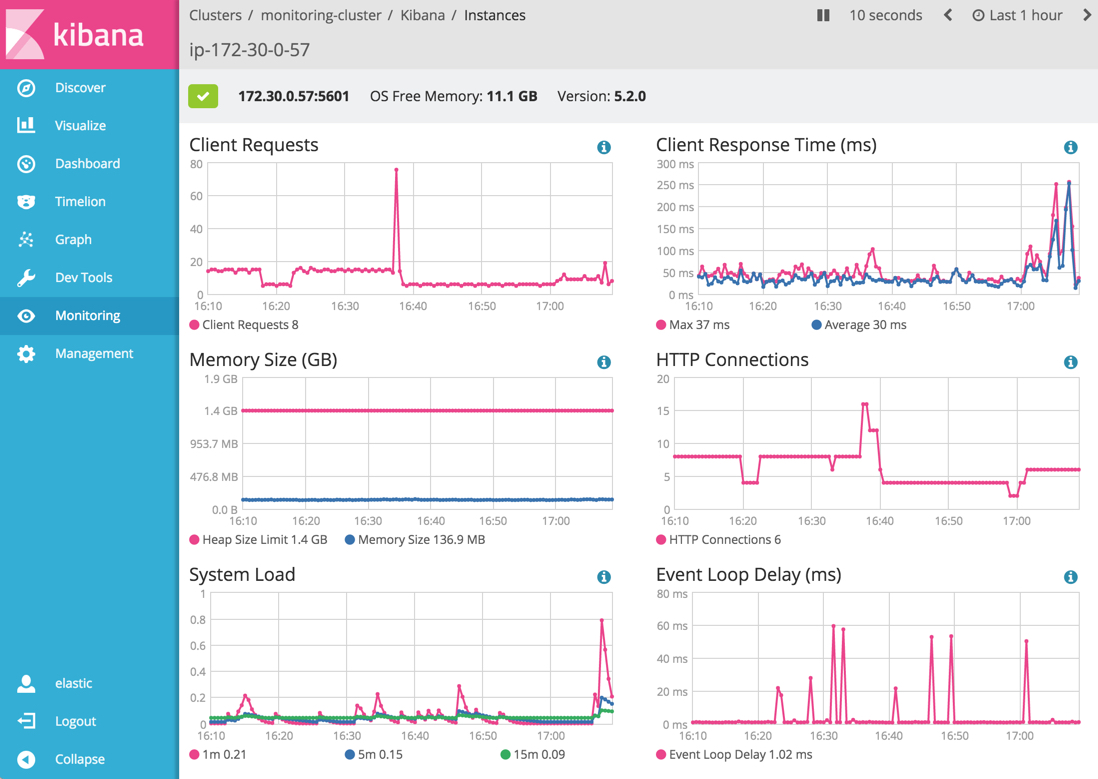 Exemple de dashboard avec Kibana
Exemple de dashboard avec Kibana
Les choses ont beaucoup changé et désormais, la suite Elastic s’est agrandie :
 Outils de la Stack Elastic
Outils de la Stack Elastic
ElasticSearch a beaucoup évolué ces dernières années. Cela tient en partie aux nouveaux marchés qu’il vise : à l’origine, on utilisait uniquement ES pour faire de la recherche full-texte, le cas d’usage était très précis et ça fonctionnait. Cela fait plusieurs années que le terme “ELK” est bien associé au stockage et à la recherche de log.
Désormais, la réorientation time-series du moteur ainsi que les nombreux outils annexes ouvrent la voie à de nouveaux usages comme le monitoring. Attention toutefois à ne pas toujours utiliser ElasticSearch en pensant qu’il est le plus adapté car il “sait” le faire : InfluxDB est une solution particulièrement performante en terme de time-series, mais plus onéreuse.
Les cas que j’ai traités dans cet article sont uniquement ceux auxquels j’ai été confronté. N’hésitez pas à commenter pour me faire part des évolutions qui vous ont particulièrement marqué.
