On assiste ces dernières années à un changement des habitudes des utilisateurs notamment sur l’Internet mondial avec la démocratisation des offres haut débits. Dans ce contexte certaines personnes se sont rendues compte qu’un modèle relationnel des données atteignait ses limites : le NoSQL allait faire son entrée dans le monde de la représentation des données.
Même si initialement le NoSQL est une réponse à la croissance toujours plus importante sur Internet, il trouve également sa place dans le monde de l’entreprise sur des échelles moindres. L’objet de cet article est de confronter les deux approches : le modèle relationnel versus le NoSQL.
Avantages :
Inconvénients :
Quelques exemples de solutions :
Avantages :
Inconvénients :
Quelques exemples de solutions (divisés en 4 familles) :
Cette catégorie de bases fonctionne comme une table associative clé/valeur ce qui en fait une base simple à mettre en place et permet un accès rapide aux informations (système de cache). Néanmoins il n’est pas possible d’indexer le contenu d’une telle base ce qui entraine un développement plus important pour garantir les performances.
Ce système est adapté dans le cadre de communication temps réel comme une messagerie en ligne.
La représentation se fait par colonnes et non par lignes comme pour un système classique, il s’agit peut-être du modèle le plus difficile à se représenter.
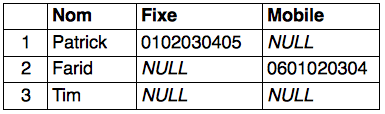
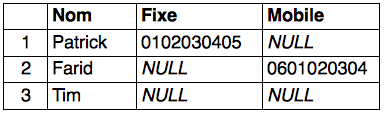 Modèle d’une base de données relationnelle
Modèle d’une base de données relationnelle
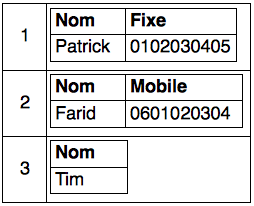 Modèle d’une base de données NoSQL famille colonne
Modèle d’une base de données NoSQL famille colonne
Cette modélisation apporte une simplification d’ajout de colonne et est capable de gérer des millions de colonnes. De plus la valeur “null” a désormais un coût de stockage de zéro. Comme les données d’une même colonne sont similaires, la compression des données en est plus efficace et les recherches “verticales” plus performantes.
Un inconvénient notable est qu’une mise à jour peut nécessiter la modification de toutes les valeurs d’une colonne pour tous les enregistrements et donc devenir très coûteux.
Cette base peut être mise en place pour gérer les commentaires d’un article de blog.
Cette famille est une extension de la famille clé/valeur en associant une clé à un document hiérarchique comme le XML, le JSON.
Ici on va pouvoir stocker toute forme de structure non plane simplement, pouvoir profiter de la puissance de l’indexation en ciblant les balises du document et ainsi bénéficier d’une interrogation simplifiée (absence de jointure).
En évoquant la mise en œuvre de requêtes une limite peut être atteinte dans la mise en place de requêtes analytiques complexes.
Dans le web, ce modèle se prête bien à la sauvegarde de profils utilisateur.
Le principe de cette famille repose sur le fait d’utiliser des objets en s’appuyant sur la théorie des graphes (représentation de nœuds et d’arcs) : chaque élément connait son(ses) voisin(s).
Un tel principe permet de mettre facilement des algorithmes de parcours de graphe (recherche du plus court chemin, nœud(s) ayant une position centrale, …) et via une indexation d’augmenter sensiblement les performances (création de listes chainées).
Cependant ce principe reste un domaine bien spécifique compliqué à utiliser concrètement et sera moins efficace dans l’exploitation des relations.
L’exemple le plus parlant est la mise en place d’un arbre généalogique : avec ce principe il est simple de retrouver les degrés de parenté entre les personnes.
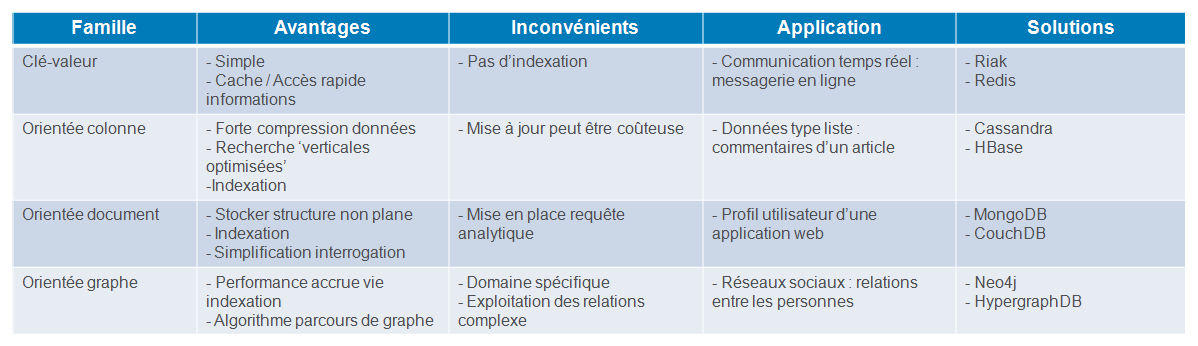
Un petit tableau récapitulatif des différentes familles
Aujourd’hui le NoSQL apporte une nouvelle façon d’appréhender la modélisation des données. Le NoSQL n’est pas là pour remplacer les bases de données relationnelles, il répond à des besoins différents mais les deux approches peuvent cohabiter. Le choix de l’une ou de l’autre sera donc fortement dépendante du contexte et du besoin.
