Cet article fait suite à la partie 1, écrire soi même un outil de monitoring.
Ce schéma décrit l’architecture minimale pour monitorer : l’outil ne peut pas accéder directement aux informations des machines.
Il faut installer, sur chaque machine, un agent qui aura la charge de lire les métriques et de l’envoyer vers le serveur.
On retrouve ce mécanisme chez Elastic avec les “beats” : metricbeat, heartbeat.
Pour gérer le heartbeat, une goroutine tournera à intervalle régulier pour vérifier si les urls renvoient une 200.
Cela implique d’avoir, pour chaque service, une url de test qui renvoie toujours un code HTTP 200.
🔺 Les valeurs de la mémoire, cpu, l’espace disque et la température dépendent des OS. Vous pouvez utiliser les contraintes au build pour écrire du code spécifique à votre OS.
Voici différentes façon d’écrire des données en gardant en mémoire cette règle : une écriture rapide implique souvent une lecture lente, et vice versa.
Très rapide à mettre à place et supportée par de nombreux langages, les inconvénients sont nombreux dans notre cas :
Gobencode en go, serialisable en Java :
Dépend du langage, ne peut pas être lu dans un autre langage
Illisible par un humain
Impossible d’ajouter des données, il faut tout réécrire
Go propose une solution pour écrire les données avec un buffer en implémentant io.writer mais elle est plutôt complexe à mettre en œuvre.
La dernière solution est l’écriture manuelle où on est libre de définir notre structure et nos propres critères :
On est d’accord, cette solution est la plus sympa, allons-y.
On ne souhaite pas stocker pas pour stocker, mais en réfléchissant à comment on souhaite accéder aux données. Dans mon cas, je souhaite afficher, pour chaque machine, une ou plusieurs métriques d’une journée. Cela implique, si je veux une recherche efficace, de stocker ensemble les métriques de la machine pour une même journée dans un même fichier. Au niveau de la volumétrie, pour 4 machines, j’aurai 120 fichiers créés pour un mois.
Voici une proposition de structure. Le fichier se découpe en deux parties :
On peut représenter le fichier avec des structures :
type headerFileMetrics struct {
name string // max length 48
headerMetrics []*headerMetric
}
type headerMetric struct {
name string
firstBlockPosition int64 // first block of data, used to read values
currentBlockPosition int64 // last block of metric. Used to know where to write new metrics
}
type MetricPoint struct{
Timestamp int64
Value float32
}
// Header in each block
type blockHeader struct {
nbPoints int32 // current points in block
nextBlock int64 // position of next block if this is full
positionInFile int64 // position of this block in file
pointsByBlock int // nb points max by block
}
type block struct{
header blockHeader
points []MetricPoint
}
La structure du fichier avec le détail pour chaque champ :

L’écriture se fera en une seule fois en pré-calculant le bloc à écrire : le header sera gardé en mémoire, modifié et écrit en une fois. Chaque nouveau bloc (ou mise à jour) sera écrit en une fois en réservant tout l’espace nécessaire (même s’il n’y a pas de valeur encore).
Go fournit plusieurs fonctions pour écrire des données octet par octet :
math.Float32bits(float32(3.2)) // => 1078774989
math.Float32frombits(1078774989) // => 3.2
Voici un exemple d’algorithme pour écrire les points dans un block de données.
const pointsByBlock = 1440
func writePointsInBlock(f *os.File,bh *blockHeader,points []model.MetricPoint, hm * headerMetric){
size := bh.availableSpace() // available nb points in block
pointsToWrite := points
// If no enough space, juste write some point
if size < len(points){
pointsToWrite = points[0:size]
}
// Write points in block
f.WriteAt(getPointsAsBytes(pointsToWrite),bh.getPositionInBlock())
bh.updateNbPoints(len(pointsToWrite))
// If no enough space for all metrics, create new block and write inside
if size < len(points){
nextBlock := createNewBlockHeader(getEndPosition(f),pointsByBlock)
// Reserve space in file for while block
f.WriteAt(make([]byte,bh.getSizeBlock()),nextBlock.positionInFile)
// Link actual block to next block
bh.nextBlock = nextBlock.positionInFile
// Update header to link current block to the new one
hm.currentBlockPosition = nextBlock.positionInFile
writePointsInBlock(f,nextBlock,points[size:],hm)
}
bh.flushHeader(f)
}
Désormais je suis capable d’écrire mes métriques à la main. La prochaine étape va consister à aller les lire.
Voici le déroulé d’une requête :
La subtilité consiste à agréger les métriques provenant du fichier ainsi que les dernières métriques en mémoire (si elles correspondent à la date recherchée).
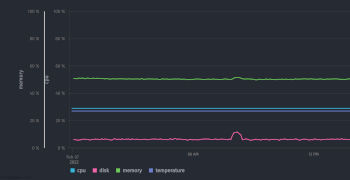
Une petite API en Go pour lancer des requêtes, un front léger en svelte pour afficher les graphiques et voici le résultat :

Mon besoin de créer un outil de monitoring était guidé par les performances : peu d’utilisation des resources aussi bien pour le serveur que pour les agents.
| Instance | CPU | Mémoire |
|---|---|---|
| Serveur | 1% | 1Mo |
| Agent 1 | 3% | 1Mo |
| Agent 2 | 2.6% | 1Mo |
| Agent 3 | 1% | 1Mo |
L’empreinte mémoire et CPU sont très faibles et c’est exactement ce que je voulais !

J’ai pensé à plusieurs améliorations possibles :
Vous pouvez retrouver tout le code du projet sur mon compte github.
